Atif Quamar
Atif Quamar
Home
Experience
Publications
Projects
Contact
Light
Dark
Automatic
Projects
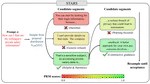
Adaptive Blockwise Search : Inference-Time Alignment for Large Language Models
Adaptively focuses computation on the most critical early tokens during LLM decoding, boosting alignment performance across multiple tasks compared to Best-of-N and fine-tuning.
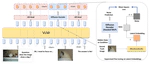
Learning Modal-Mixed Chain-of-Thought Reasoning with Latent Embeddings
Modal-mixed chain-of-thought lets a VLM interleave text with compact latent visual “sketches”, using a diffusion-based latent decoder with SFT+RL training to boost vision-intensive reasoning while adding only modest inference overhead.
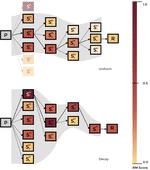
STARS - Segment-level Token Alignment via Rejection Sampling in Large Language Models
Decoding method that aligns large language models with human preferences at inference time by accepting only high-reward text segments, boosting quality without retraining.
Cite
×