Adaptive Blockwise Search : Inference-Time Alignment for Large Language Models
Most inference-time alignment methods spend the same effort on every token. That is wasteful, because early tokens often set the path for the whole answer. The paper introduces ADASEARCH and ADABEAM, which reallocate a fixed compute budget to focus more on the first blocks of text. Across eight LLMs and multiple tasks, this yields higher win-rates than strong Best-of-N baselines and even some fine-tuned models, all under the same budget.
Why it matters: The approach is training-free, works at decode time, and improves harmlessness, sentiment control, and math reasoning. Reported gains exceed 10 percent for harmlessness, 33 percent for sentiment, and 24 percent for reasoning relative to Best-of-N.
Approach
Blockwise search with adaptive budgets
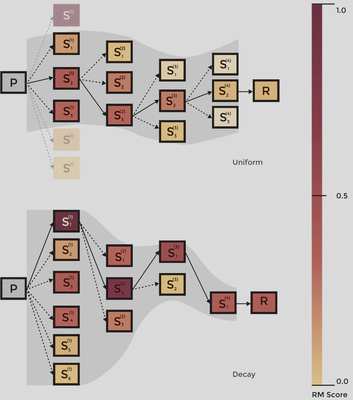
Generation is divided into fixed-size blocks. Instead of sampling a full response N times, ADASEARCH sets a schedule α = [α(1), …, α(K)] that decides how many samples to draw for each block, with a fixed total budget C. The greedy pick per block uses a process reward model (PRM) to score partial continuations, then accepts the best segment and moves on. Common schedules: Uniform, Decay (front-loaded), Growth (back-loaded).
Mathematically, the schedule satisfies ∑i α(i) = C. Decay is exponential with rate γ, which concentrates more samples on early blocks.
Reward models, tasks, and datasets
PRMs used:
- DeBERTa-v3-large-v2 for helpful and harmless generation.
- DistilBERT-base for sentiment control.
- Qwen-2.5-Math for reasoning quality.
Datasets:
- HH-RLHF and HarmfulQA for safety.
- IMDB for positive sentiment.
- GSM8K for math reasoning.
Extending to tree search
ADABEAM applies the same schedule idea to reward-guided beam search by varying beam width per block. Compute is matched across schedules using a cost function and decay again allocates more search early.
What we achieved
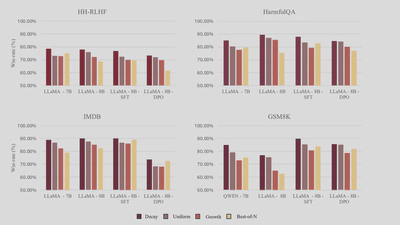
Front-loading wins: Decay > Uniform > Growth across tasks, at equal compute. This holds for harmlessness, sentiment, and reasoning.
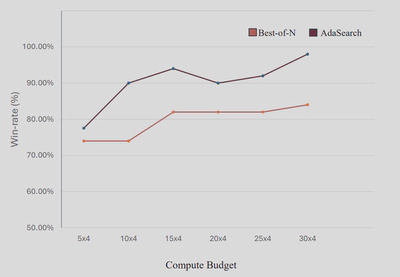
Against Best-of-N: ADASEARCH improves win-rates over compute-matched Best-of-N on all four datasets for many 7B to 8B models. Table 1 shows consistent gains, for example on IMDB and GSM8K.
Quality and fluency: On DeepSeek-7B, ADASEARCH achieves higher reward scores with competitive perplexity, diversity, and coherence compared to baselines.
Beats fine-tuning in some settings: With the same inference budget, ADASEARCH surpasses SFT on IMDB and improves over DPO in safety comparisons.
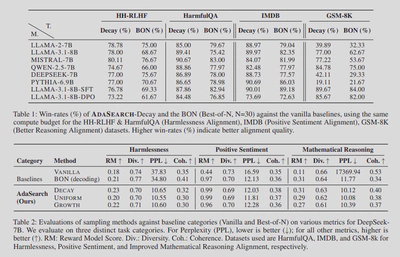
Small models can punch up: With ADASEARCH-Decay, several ~7B models achieve win-rates that beat a LLaMA-405B baseline in head-to-head comparisons on HH-RLHF. See Table 3 for per-model numbers.
Generalizes to beam search: ADABEAM with a Decay schedule outperforms uniform Tree-BoN and Growth on HH-RLHF across models.
Ablations: Intermediate decay rates work best. Win-tie peaks near γ = 0.4, which balances early exploration and later coverage.
Future Work
Practical recipe. Keep compute fixed, shift more of it to the first blocks. This is drop-in for sequential decoding and tree search.
Flexible objectives. You can mix rewards at decode time, for example balancing non-toxicity with positive sentiment using a weighted combination. Static fine-tuned models cannot do this without retraining.
Limits and next steps.
- Reasoning gains depend on PRM quality. Better process-level reward models should help.
- Learn schedules from data or adapt them online.
- Explore adaptive block sizes and uncertainty-aware allocation.