STARS - Segment-level Token Alignment via Rejection Sampling in Large Language Models
We proposed STARS (Segment-level Token Alignment via Rejection Sampling) - a decoding method that improves the alignment of large language models (LLMs) with human preferences—without costly retraining. Instead of evaluating entire generated responses or every single token, STARS breaks outputs into short, fixed-size segments. Each segment is only accepted if it meets an adaptive reward threshold, ensuring high-quality, harmless, and preference-aligned responses.
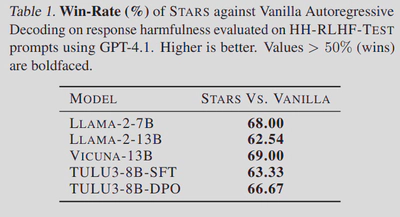
This approach bridges the gap between efficiency and quality: it matches or exceeds the alignment performance of resource-heavy strategies like Best-of-N, but with significantly fewer LLM calls. In tests across multiple 7B–13B open-source models, STARS improved win-rates by 20–25 percentage points over standard decoding, even enabling smaller aligned models to outperform larger, unaligned ones.
By focusing on inference-time alignment, STARS offers a practical, scalable, and compute-conscious solution for safer AI deployments.
Will add more details soon…