Learning Modal-Mixed Chain-of-Thought Reasoning with Latent Embeddings
TLDR: This work proposes a way for multimodal models to reason with both words and tiny visual “sketches” that live in latent space. These sketches are generated on the fly, guided by the model’s language reasoning, and they help on vision intensive puzzles. The team trains this in two stages, first with supervised traces, then with reinforcement learning. Results across many tasks show steady gains over language only chain of thought.
Why this is interesting
Chain of thought made language models better at math and logic by getting them to show their work. That works less well when the hard part is visual, like tracking shapes, rotations, or tiny differences that are painful to describe in words. The paper’s core idea is simple and appealing. Let the model switch between words and compact visual latents during reasoning, so it can offload the purely visual bits to lightweight embeddings while keeping language for high level logic.
The one sentence idea
Interleave normal text tokens with short bursts of visual latent tokens that act like internal sketches, then use those sketches to ground the next steps of the textual chain.
How it works, step by step
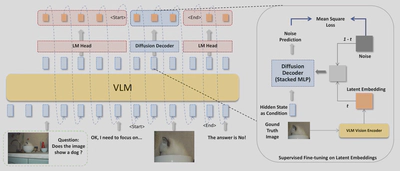
VLM as its own visual encoder.
Instead of inventing a new image space, the method reuses the vision encoder and connector from the base VLM to define the latent space. During training the language backbone learns to reconstruct the VLM’s own visual embeddings for intermediate images. This keeps the new latents aligned with what the model already understands.A tiny diffusion decoder for detail.
A diffusion head turns a hidden language state into a compact visual latent. The language side specifies intent, the lightweight diffusion module carries fine grained perceptual detail. This split reduces forgetting and keeps the VLM focused on reasoning rather than pixel minutiae.Two special control tokens.
The model writes normal text until it emits<START>, then it generates K latent embeddings autoregressively, closes with<END>, and goes back to text. You can read the final reasoning trace as words, a small latent sketchpad, then more words, and so on.Two stage training recipe.
- Supervised fine tuning: learn the interleaved format using a joint objective that mixes next token prediction with diffusion reconstruction of the latents.
- Reinforcement learning: roll out self generated traces and reward correct answers, which teaches when to switch modalities and how long the sketch segments should be. The training uses a group relative preference objective with a KL penalty for stability.
What problems this helps with
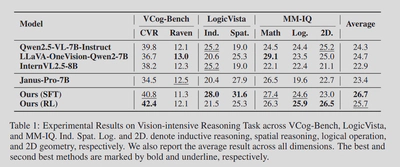
The team evaluates on multimodal tasks that demand either careful perception or composed visual reasoning. Examples include abstract pattern completion, spatial logic, spot the difference, auxiliary geometric lines, and visual search. Across these, modal mixed chain of thought beats language only chain of thought and is competitive with or better than strong VLM baselines.
A few numbers that stand out
- Vision intensive reasoning: On spatial and inductive tasks, the modal mixed model improves over the base VLM variants. Average gains are larger where visual structure matters most.
- Perception heavy tasks: On visual search, spot the difference, and auxiliary lines, the approach lifts the base model’s scores. The RL phase helps fine grained perception.
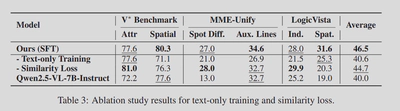
- Ablations: Removing latents and training on text only hurts. Replacing the diffusion head with a simple similarity loss helps a bit, but still trails the full method. This supports the claim that explicit latent generation matters.
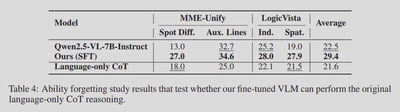
- Forgetting check: The fine tuned VLM retains language only chain of thought ability at a comparable level once the latent machinery is removed at test time. The alignment choice and modular decoder help avoid catastrophic forgetting.
- Efficiency: Latents add tokens and a small diffusion loop, so latency increases but stays within a reasonable range for the reported setup.
Where it struggled and what comes next
RL helped perception tasks a lot, yet some abstract logic dimensions saw smaller gains. Long output patterns and very abstract rules were probably underrepresented in the RL data. Better reward design and longer trace coverage could help.
Scaling to other modalities like audio or 3D seems natural. Uncertainty aware policies, smarter decisions about when to sketch, and larger pretraining on the new architecture all look promising.
What to try if you build with this idea
- Start with a strong VLM and keep its vision encoder frozen while you bolt on a small diffusion head for latent sketches.
- Curate a few interleaved traces per task that really require seeing and not just telling. Then do supervised fine tuning with the joint loss.
- Add RL only after you get clean SFT traces, and monitor long reasoning outputs for regressions.
Closing thoughts
This work takes a pragmatic step toward models that can draw to think, not as full images, but as compressed latents that are cheap to produce and easy to reuse. It keeps the language model in control, brings a tiny generator to handle visuals, and shows that even small sketches can unlock harder vision heavy reasoning. The paper appears to be under double blind review, and the authors say they will release code and data.