Adaptive Blockwise Search: Inference-Time Alignment for Large Language Models
Adaptively focuses computation on the most critical early tokens during LLM decoding, boosting alignment performance across multiple tasks compared to Best-of-N and fine-tuning.
Most inference-time alignment methods spend the same effort on every token. That is wasteful, because early tokens often set the path for the whole answer. The paper introduces ADASEARCH and ADABEAM, which reallocate a fixed compute budget to focus more on the first blocks of text. Across eight LLMs and multiple tasks, this yields higher win-rates than strong Best-of-N baselines and even some fine-tuned models, all under the same budget.
Why it matters: The approach is training-free, works at decode time, and improves harmlessness, sentiment control, and math reasoning. Reported gains exceed 10 percent for harmlessness, 33 percent for sentiment, and 24 percent for reasoning relative to Best-of-N.
Approach
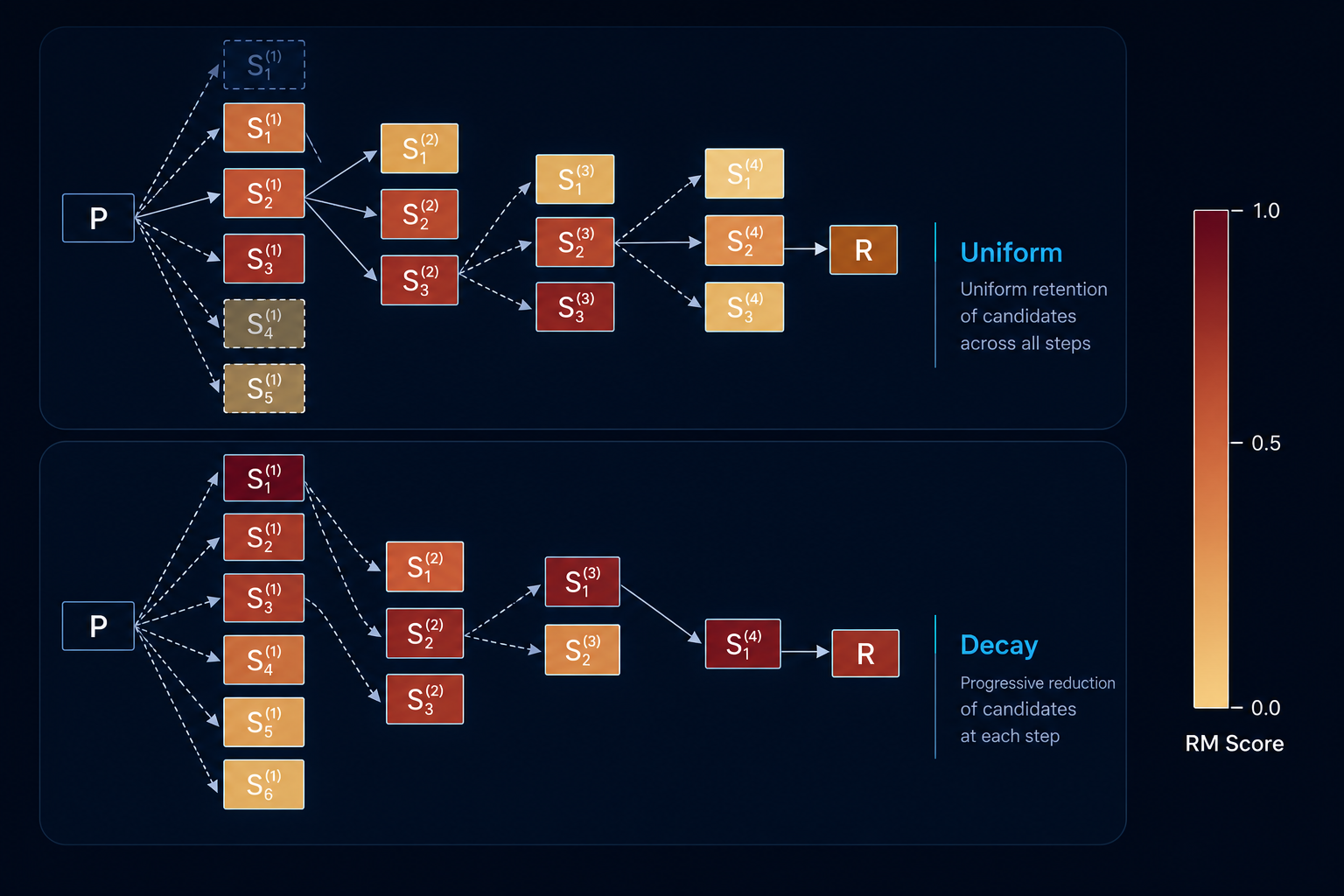
Generation is divided into fixed-size blocks. Instead of sampling a full response N times, ADASEARCH sets a schedule that decides how many samples to draw for each block, with a fixed total budget. The greedy pick per block uses a process reward model to score partial continuations, then accepts the best segment and moves on. Common schedules include Uniform, Decay, and Growth.
ADABEAM applies the same schedule idea to reward-guided beam search by varying beam width per block. Compute is matched across schedules using a cost function and decay again allocates more search early.
What We Achieved
- Decay outperforms Uniform and Growth across tasks at equal compute.
- ADASEARCH improves win-rates over compute-matched Best-of-N on HH-RLHF, HarmfulQA, IMDB, and GSM8K for many 7B to 8B models.
- On DeepSeek-7B, ADASEARCH achieves higher reward scores with competitive perplexity, diversity, and coherence compared to baselines.
- With the same inference budget, ADASEARCH surpasses SFT on IMDB and improves over DPO in safety comparisons.
- ADABEAM with a Decay schedule outperforms uniform Tree-BoN and Growth on HH-RLHF across models.
Future Work
- Better process-level reward models should help reasoning gains.
- Learn schedules from data or adapt them online.
- Explore adaptive block sizes and uncertainty-aware allocation.