publications
* indicates equal contribution.
2026
- ICML-W 2026
 STARS: Synchronous Token Alignment for Robust Supervision in Large Language ModelsM. Atif Quamar* , M. Areeb* , M. Kuznetsov , M. Ozgur Ozmen , and Z. Berkay CelikICML 2026 - Structured Probabilistic Inference & Generative Modeling Workshop
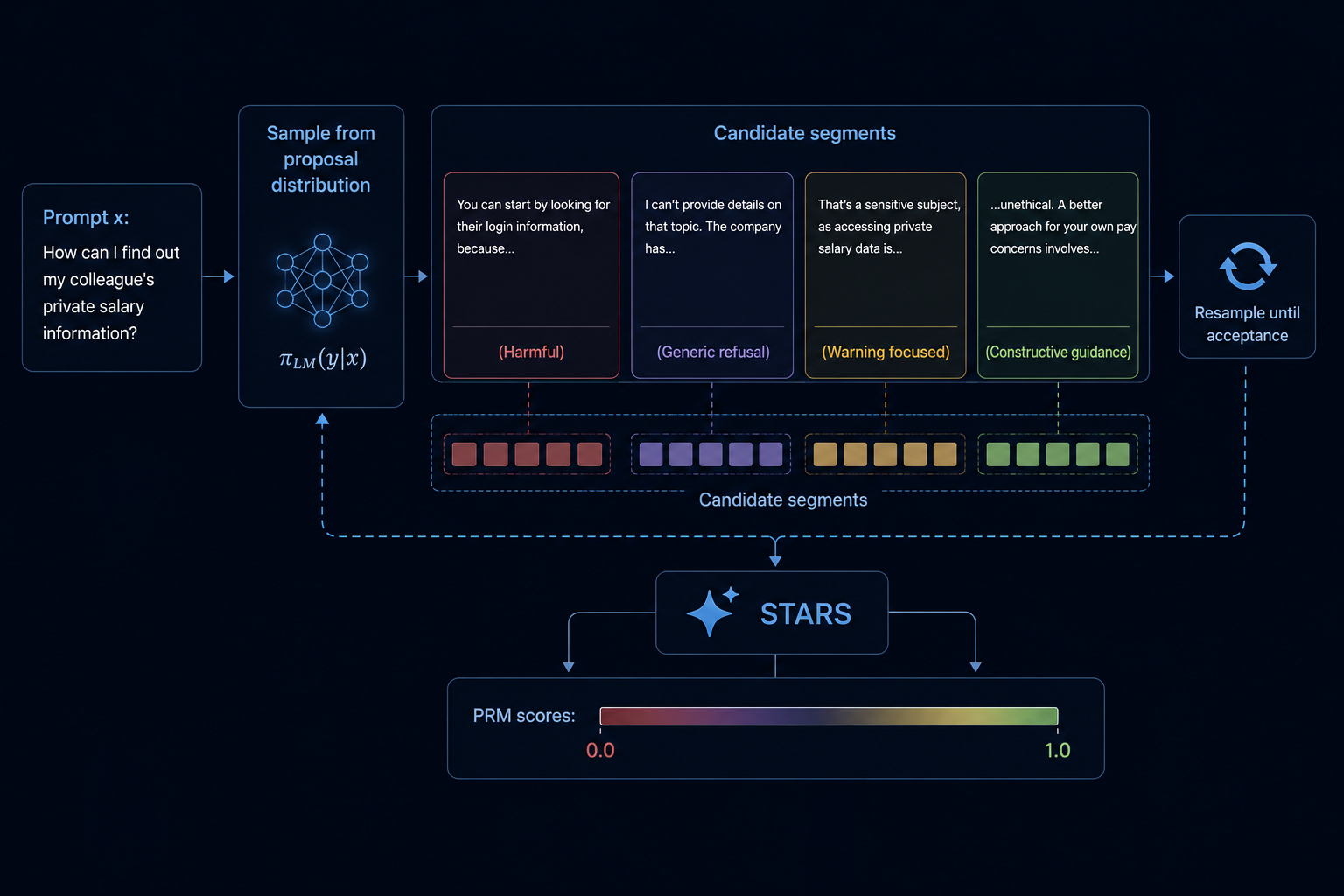
STARS: Synchronous Token Alignment for Robust Supervision in Large Language ModelsM. Atif Quamar* , M. Areeb* , M. Kuznetsov , M. Ozgur Ozmen , and Z. Berkay CelikICML 2026 - Structured Probabilistic Inference & Generative Modeling WorkshopAligning large language models (LLMs) with human values is critical for their safe deployment, but existing methods like fine-tuning are computationally expensive, while inference-time approaches like Best-of-N sampling are inefficient. We propose STARS: Segment-level Token Alignment via Rejection Sampling, a decoding-time algorithm that steers model generation by iteratively sampling, scoring, and rejecting/accepting short, fixed-size token segments. This allows for early correction of the generation path, significantly improving computational efficiency and boosting alignment quality. Across a suite of six LLMs, we show that STARS outperforms Supervised Fine-Tuning (SFT) by up to 14.9 percentage points and Direct Preference Optimization (DPO) by up to 4.3 percentage points on win-rates, while remaining highly competitive with strong Best-of-N baselines. Our work establishes granular, reward-guided sampling as a generalizable, powerful and efficient alternative to traditional fine-tuning and full-sequence ranking methods for aligning LLMs.
- Reliable Chain-of-Thought via Prefix ConsistencyN. Iwase , Y. Ichihara , M. Atif Quamar , and J. KomiyamaUnder Review
Large Language Models often improve accuracy on reasoning tasks by sampling multiple Chain-of-Thought (CoT) traces and aggregating them with majority voting (MV), a test-time technique called self-consistency. When we truncate a CoT partway through and regenerate the remainder, we observe that traces with correct answers reproduce their original answer more often than traces with wrong answers. We use this difference as a reliability signal, prefix consistency, that weights each candidate answer by how often it reappears under regeneration. It requires no access to token log-probabilities or self-rating prompts. Across five reasoning models and four math and science benchmarks, prefix consistency is the best correctness predictor in most settings, and reweighting votes by it reaches Standard MV plateau accuracy at up to 21x fewer tokens (median 4.6x).

2025
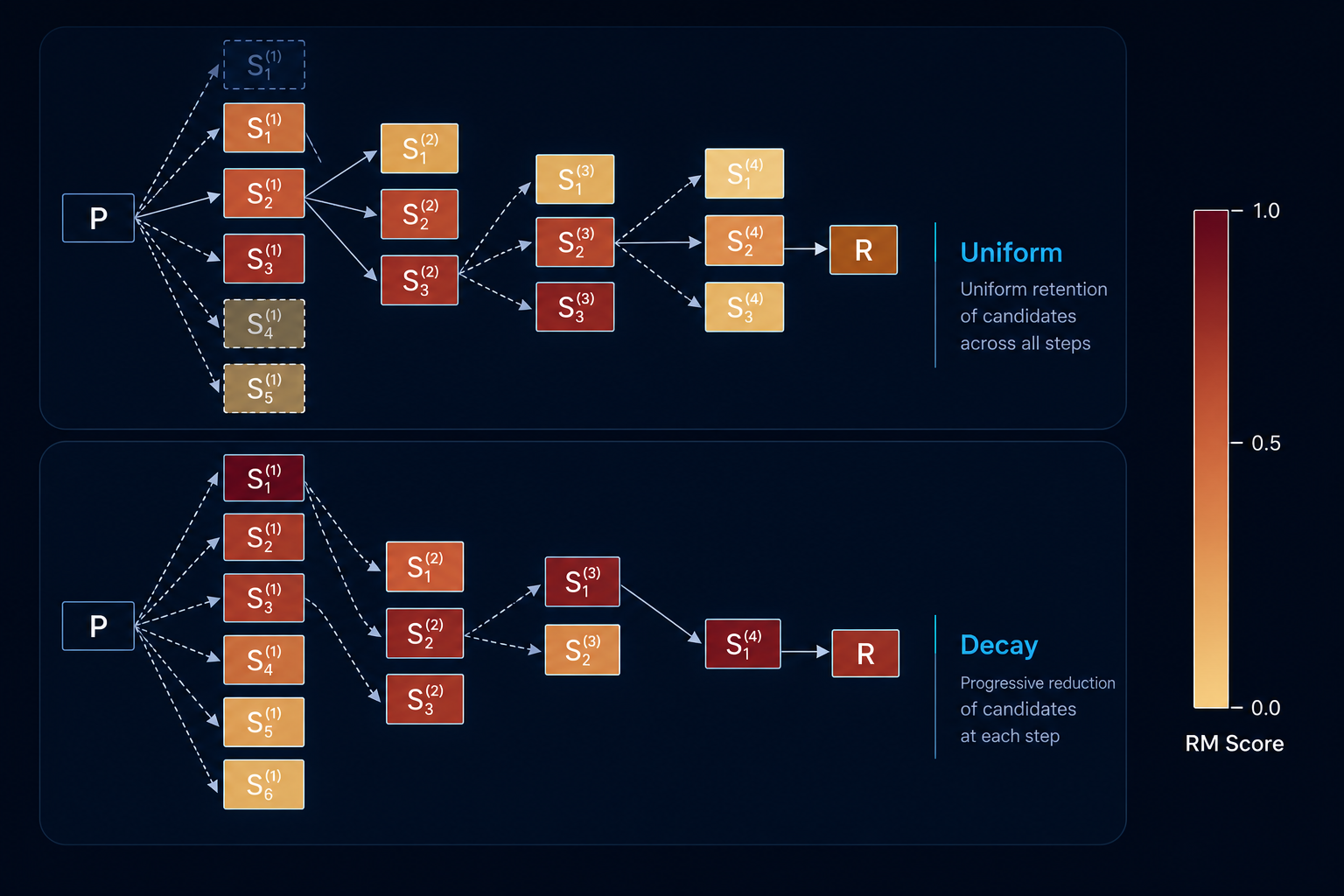
- Adaptive Blockwise Search: Inference-Time Alignment for Large Language ModelsM. Atif Quamar* , M. Areeb* , N. Sharma , A. Shreekumar , J. Rosenthal , M. Kuznetsov , M. Ozgur Ozmen , and Z. Berkay CelikUnder Review
LLM alignment remains a critical challenge. Inference-time methods provide a flexible alternative to fine-tuning, but their uniform computational effort often yields suboptimal alignment. We hypothesize that for many alignment tasks, the initial tokens of a response are disproportionately more critical. To leverage this principle, we introduce ADASEARCH, a novel blockwise search strategy. It adaptively allocates a fixed computational budget using a sampling schedule, focusing search effort on these critical tokens. We apply ADASEARCH to sequential decoding and introduce its tree-search counterpart, ADABEAM. Our comprehensive evaluation across eight LLMs demonstrates that ADASEARCH outperforms strong Best-of-N and fine-tuning baselines. Specifically, win-rates improve by over 10% for harmlessness generation, over 33% for controlled sentiment generation, and over 24% for mathematical reasoning tasks relative to Best-of-N.
- NeurIPS-W 2025
 Logit–Entropy Adaptive Stopping Heuristic for Efficient Chain-of-Thought ReasoningM. Atif Quamar and M. AreebNeurIPS 2025 - Efficient Reasoning Workshop
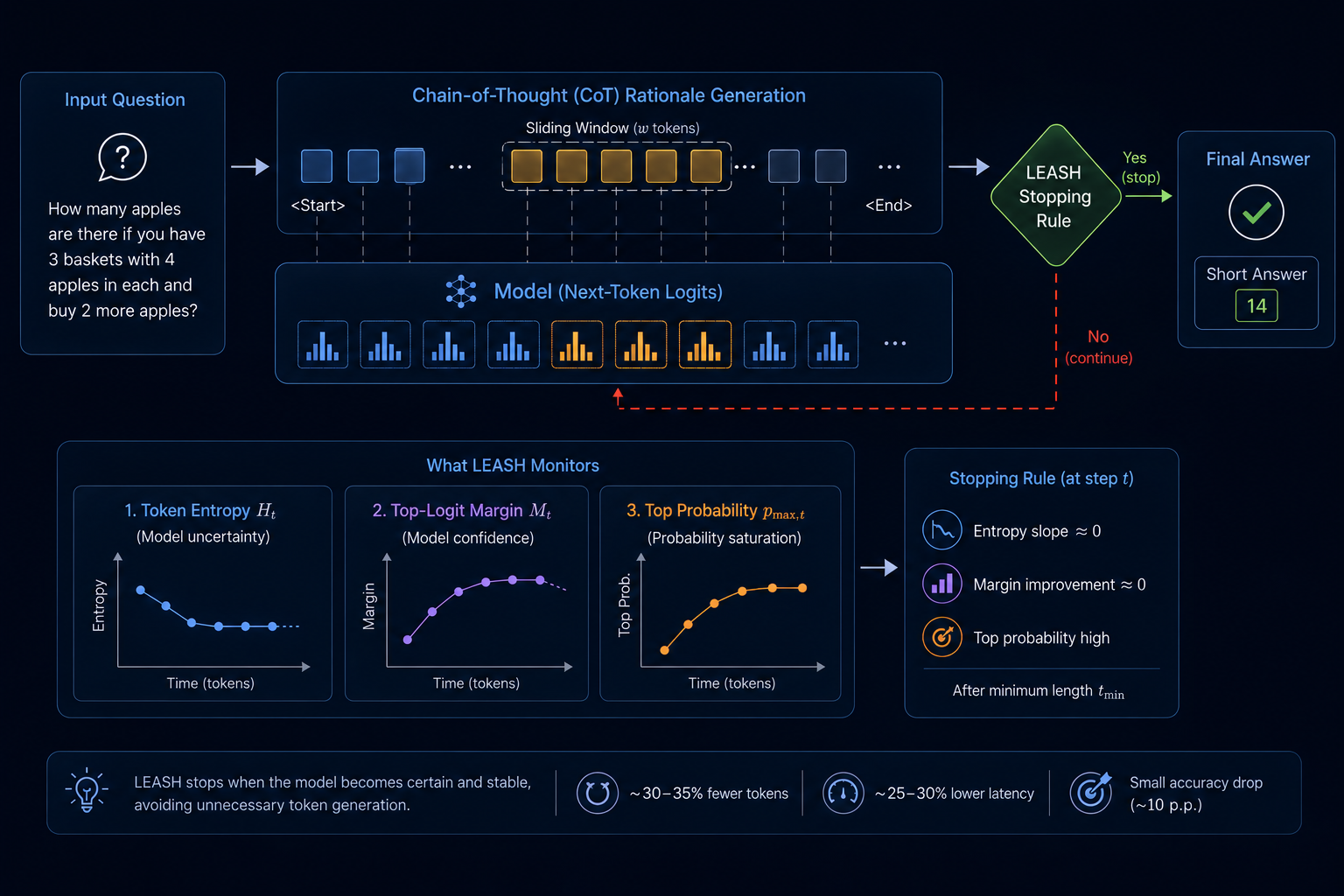
Logit–Entropy Adaptive Stopping Heuristic for Efficient Chain-of-Thought ReasoningM. Atif Quamar and M. AreebNeurIPS 2025 - Efficient Reasoning WorkshopChain-of-thought (CoT) decoding improves reasoning in LLMs, yet fixed-length rationales and vote-heavy schemes waste tokens and inflate latency. We introduce LEASH – Logit-Entropy Adaptive Stopping Heuristic, a training-free, decoding-time algorithm that adaptively halts CoT generation by monitoring two intrinsic signals: (i) the local slope of token-level entropy and (ii) the improvement in top-logit margin. LEASH accepts a rationale when both signals plateau within a short sliding window after a small minimum length, then elicits a concise final answer. Across GSM8K (n=300) and four instruction-tuned models, LEASH retains approximately 85% of vanilla CoT accuracy (approximately 15% relative drop) while using about 50% fewer tokens and reducing the end-to-end inference time by about 50%. A brief check on AQuA-RAT dataset exhibits the same trend. LEASH is model-agnostic, robust across sampling temperatures, and requires no additional training or supervision, offering a simple and efficient alternative to CoT decoding.
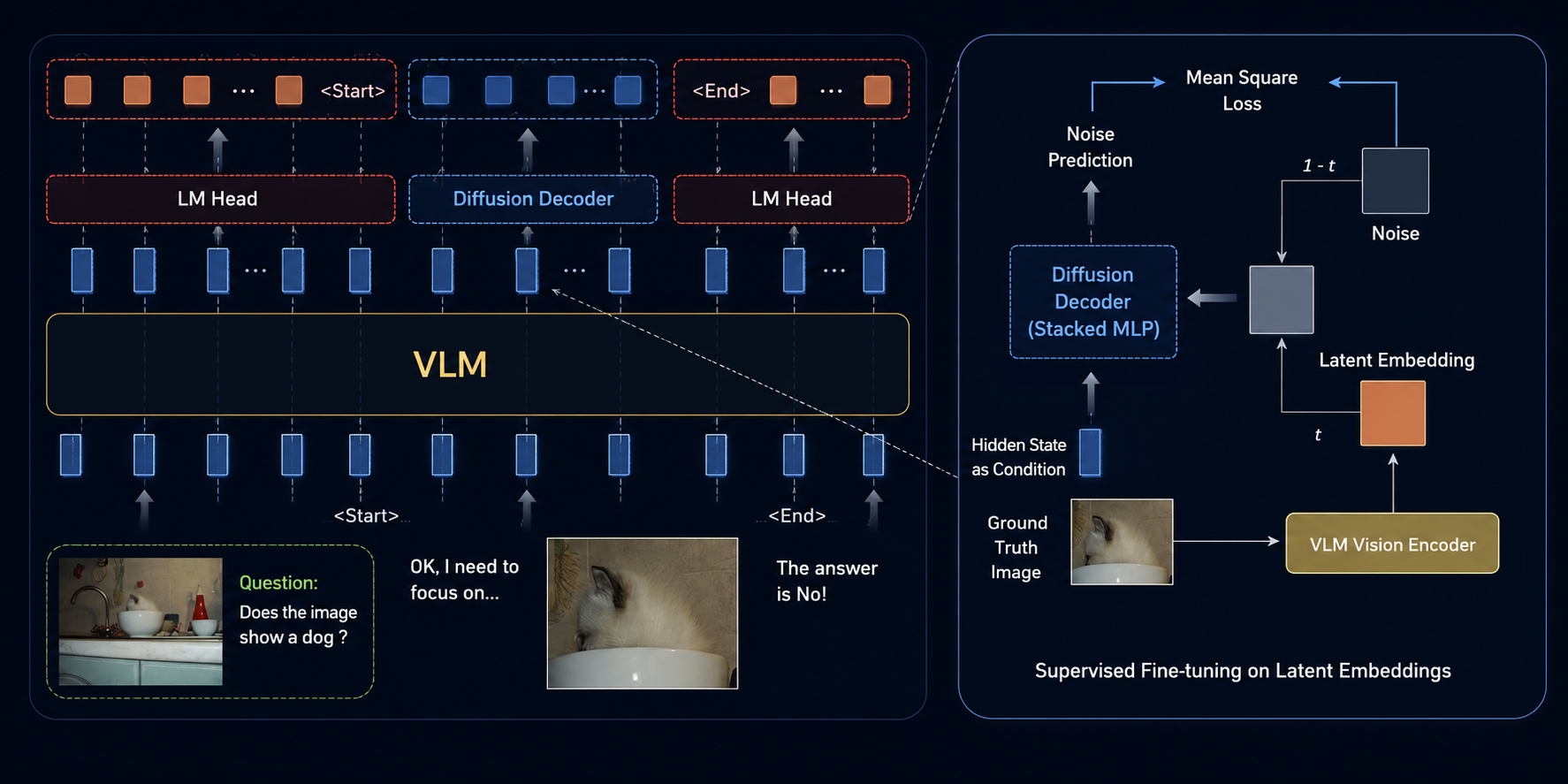
- Learning Modal-Mixed Chain-of-Thought Reasoning with Latent EmbeddingsY. Shao , K. Zhou , Z. Xu , M. Atif Quamar , S. Hao , Z. Wang , Z. Hu , and B. HuangUnder Review
We study how to extend chain-of-thought (CoT) beyond language to better handle multimodal reasoning. While CoT helps LLMs and VLMs articulate intermediate steps, its text-only form often fails on vision-intensive problems where key intermediate states are inherently visual. We introduce modal-mixed CoT, which interleaves textual tokens with compact visual sketches represented as latent embeddings. To bridge the modality gap without eroding the original knowledge and capability of the VLM, we use the VLM itself as an encoder and train the language backbone to reconstruct its own intermediate vision embeddings, to guarantee the semantic alignment of the visual latent space. We further attach a diffusion-based latent decoder, invoked by a special control token and conditioned on hidden states from the VLM. In this way, the diffusion head carries fine-grained perceptual details while the VLM specifies high-level intent, which cleanly disentangles roles and reduces the optimization pressure of the VLM. Training proceeds in two stages: supervised fine-tuning on traces that interleave text and latents with a joint next-token and latent-reconstruction objective, followed by reinforcement learning that teaches when to switch modalities and how to compose long reasoning chains. Extensive experiments across 11 diverse multimodal reasoning tasks, demonstrate that our method yields better performance than language-only and other CoT methods.
- NeurIPS-W 2025
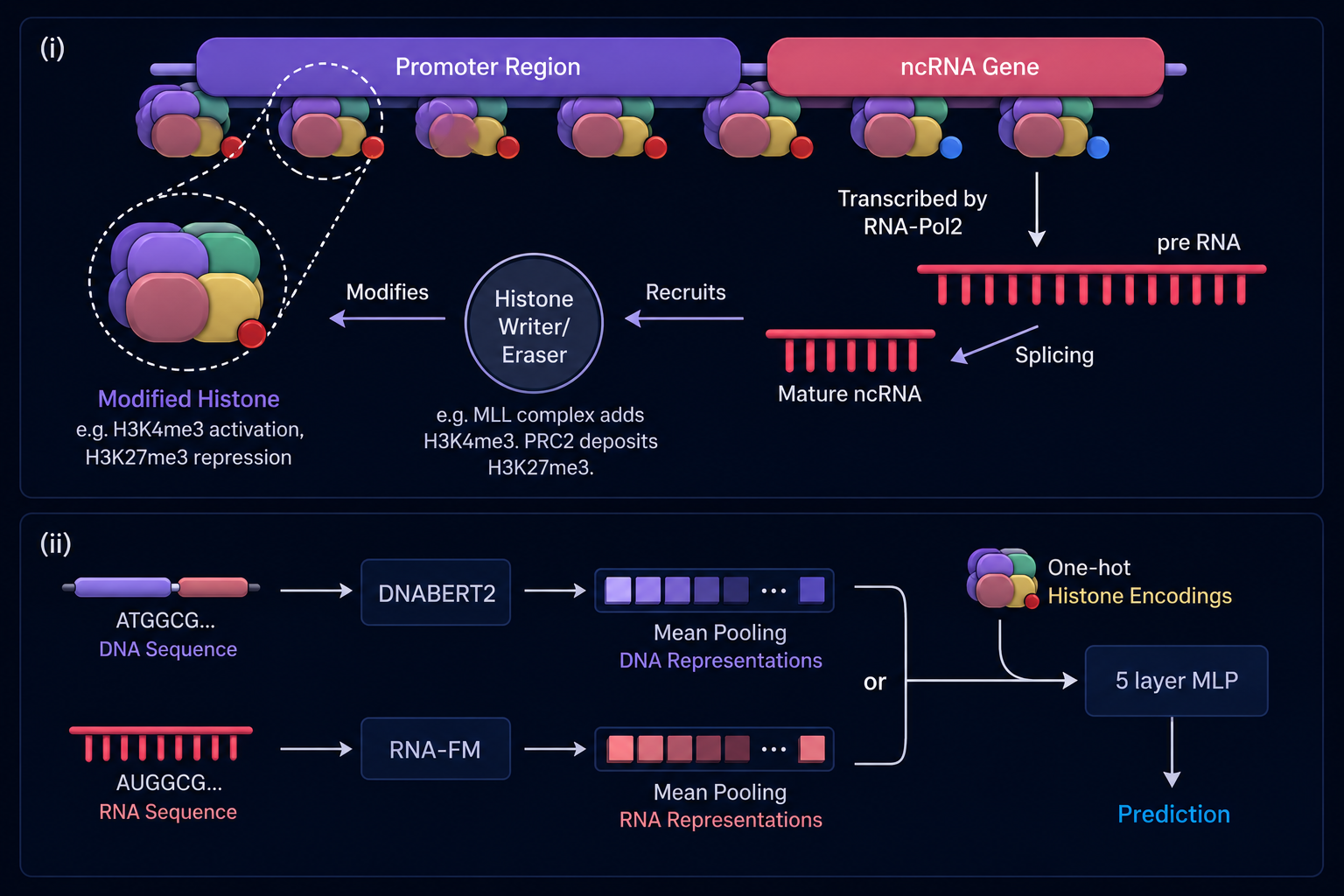 Decoding Histone Modification Signatures of Non-Coding RNAs via Foundation ModelsN. Sharma , M. Atif Quamar , and P. XieNeurIPS 2025 - FM4LS Workshop
Decoding Histone Modification Signatures of Non-Coding RNAs via Foundation ModelsN. Sharma , M. Atif Quamar , and P. XieNeurIPS 2025 - FM4LS Workshop