Learning Modal-Mixed Chain-of-Thought Reasoning with Latent Embeddings
Modal-mixed chain-of-thought lets a VLM interleave text with compact latent visual sketches, using a diffusion-based latent decoder with SFT+RL training to boost vision-intensive reasoning while adding only modest inference overhead.
This work proposes a way for multimodal models to reason with both words and tiny visual sketches that live in latent space. These sketches are generated on the fly, guided by the model’s language reasoning, and they help on vision intensive puzzles. The team trains this in two stages, first with supervised traces, then with reinforcement learning. Results across many tasks show steady gains over language only chain of thought.
Why This Is Interesting
Chain of thought made language models better at math and logic by getting them to show their work. That works less well when the hard part is visual, like tracking shapes, rotations, or tiny differences that are painful to describe in words. The paper’s core idea is simple and appealing: let the model switch between words and compact visual latents during reasoning, so it can offload the purely visual bits to lightweight embeddings while keeping language for high level logic.
How It Works
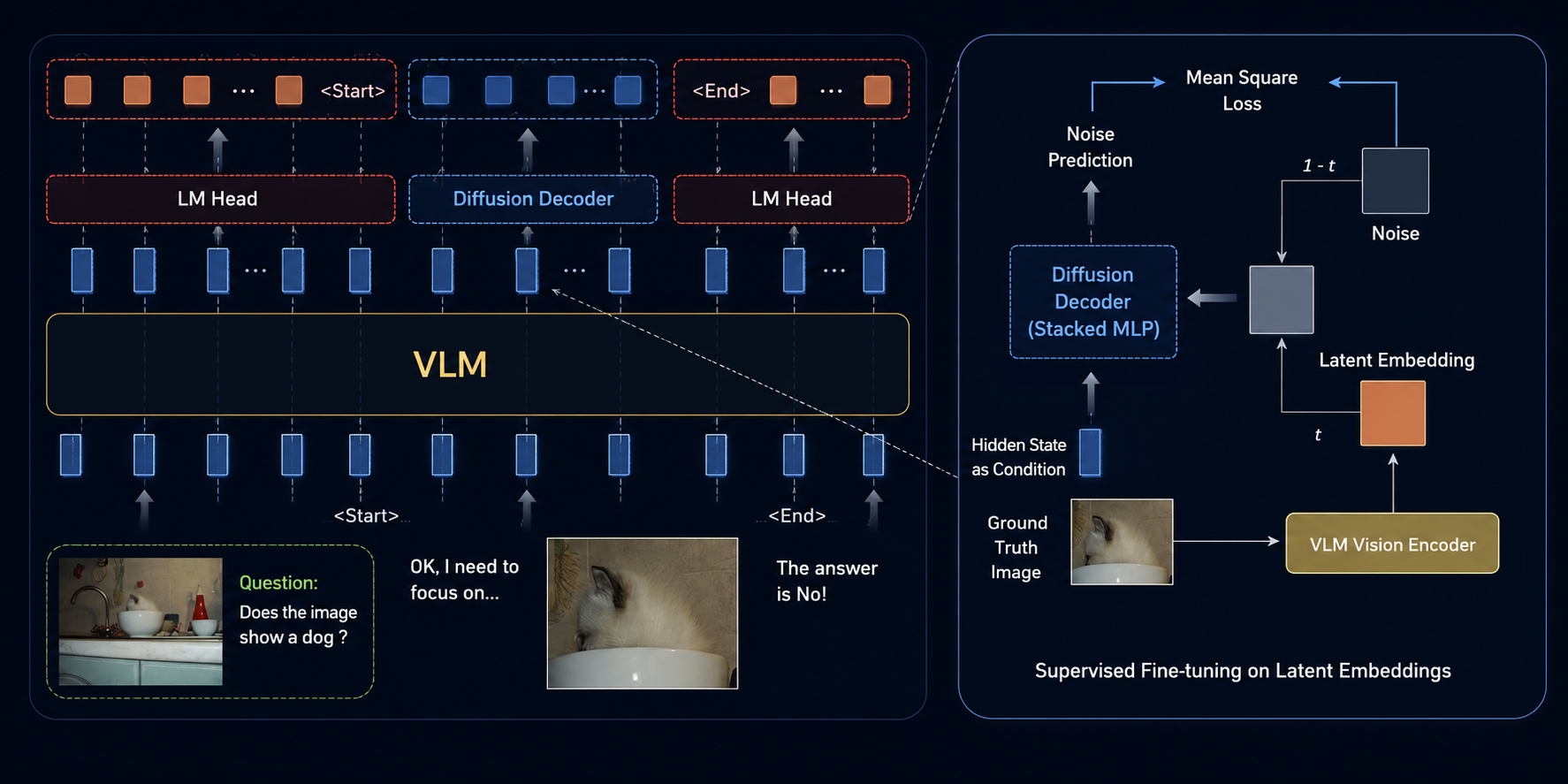
- The method reuses the vision encoder and connector from the base VLM to define the latent space.
- A diffusion head turns a hidden language state into a compact visual latent.
- The model writes normal text until it emits a start control token, generates latent embeddings autoregressively, closes with an end control token, and goes back to text.
- Training mixes supervised fine tuning on interleaved traces with reinforcement learning that teaches when to switch modalities and how long the sketch segments should be.
Results And Limits
- On spatial and inductive tasks, the modal mixed model improves over the base VLM variants.
- On visual search, spot the difference, and auxiliary lines, the approach lifts the base model’s scores.
- Removing latents and training on text only hurts.
- Replacing the diffusion head with a simple similarity loss helps a bit, but still trails the full method.
- RL helped perception tasks a lot, yet some abstract logic dimensions saw smaller gains.